
The science of science
Probabilistic models of our thinking


It’s 6:00 AM. The alarm clock is blasting, but you are having a hard time getting out of bed. You don’t feel well. Your muscles are weak, and your head is exploding. After a brief struggle, you manage to call a doctor and list all the symptoms. Your sore throat makes speaking painful.
“It’s probably just the flu“, she says.
Interactions like this are everyday occurrences. Yet, we hardly think about the reasoning process behind them. After all, you could have been hungover.
Similarly, if the police find a murder weapon at your house, they’ll suspect that you are the killer. The two are related, but not the same. For instance, the murder weapon could have been planted.
The bulk of humanity’s knowledge is obtained in this manner: we collect evidence, then explain it with various hypotheses.
How do we infer the underlying cause from observing the effect? Most importantly, how can we avoid fooling ourselves into false conclusions?
You are (probably) not surprised: there’s mathematics behind the curtain.
Thinking in absolutes
First, let’s talk about how we think. On the most basic level, our knowledge about the world is stored in propositions. In a mathematical sense, a proposition is a declaration that is either true or false. (In binary terms, true is denoted by 1 and false is denoted by 0.)
“The sky is blue.“
“There are infinitely many prime numbers.“
“1 + 1 = 3.“
“I got the flu.“
Propositions are often abbreviated as variables such as A = "it's raining outside".
Determining the truth value of a given proposition using evidence and reasoning is called inference. Sounds simple enough!
Famous last words.
Enter the world of mathematical logic.
Mathematical logic 101
So, we have propositions like A = "it's raining outside", or B = "the sidewalk is wet". As you might have already noted, we need more expression power.
We can formulate complex propositions from smaller building blocks with logical connectives. Consider the proposition "if it is raining outside, then the sidewalk is wet". This is the combination of A and B, strung together by the implication connective.
There are four essential connectives:
• NOT (¬), also known as negation,
• AND (∧), also known as conjunction,
• OR (∨), also known as disjunction,
• THEN (→), also known as implication.
Connectives are defined by the truth values of the resulting propositions. For instance, if A is true, then NOT A is false; if A is false, then NOT A is true. Denoting true by 1 and false by 0, we can describe connectives with truth tables. Here is the one for negation (¬).

AND (∧) and OR (∨) connect two propositions. A ∧ B is true if both A and B are true, and A ∨ B is true if either one is.

The implication connective THEN (→) formalizes the deduction of a conclusion B from a premise A. By definition, A → B is true if B is true or both A and B are false. An example: if "it's raining outside", THEN "the sidewalk is wet".

The inference process
Let’s refine the inference process. A proposition is either true or false, fair and square. How can we determine that in practice? Say, how do we find the truth value of the proposition “there are infinitely many prime numbers“?
Using evidence and deduction. Duh. Like Sherlock Holmes solving a crime by connecting facts, we rely on knowledge of the form “if A, then B“.
Our knowledge about the world is stored in true implications. For example,
“If it is raining, then the sidewalk is wet.“
“If ABC is a right triangle, then A² + B² = C².“
“If a system is closed, then its entropy cannot decrease.“
Notice that A → B doesn’t imply B → A. If it rains, the sidewalk is wet; but if the sidewalk is wet, it’s not necessarily because of rain. Maybe someone spilled a barrel of water.
The implication can be translated into the language of set theory. (As all the other connectives.) While AND corresponds to intersection and OR to union, the implication is the subset relation. Keep this in mind, as it’s going to be important.

During inference, we use implications in the following way.
If A, then B.
A.
Therefore B.
This is the famous modus ponens. If it sounds abstract, here is a concrete example.
If it is raining, the sidewalk is wet.
It is raining.
Therefore, the sidewalk is wet.
Thus, we can infer the state of the sidewalk without looking at it. This is bigger than it sounds: modus ponens is a cornerstone of scientific thinking. We would still be living in caves without it.
Modus ponens enables us to build robust skyscrapers of knowledge.
However, it’s not all perfect. Classical deductive logic might help to prove the infinity of prime numbers, but it fails spectacularly when confronted with inference problems outside the realms of mathematics and philosophy.
In the following, we’ll talk about why.
Thinking in probabilities
Let’s revisit the story kicking off this whole journey: “muscle fatigue, headache, sore throat → flu“. This is certainly not true in an absolute sense, as these symptoms resemble how you would feel after shouting and drinking excessively during a metal concert. Which is far from the flu.
Yet, a positive diagnosis of flu is plausible. Given the evidence at hand, our belief is increased in the hypothesis.
Unfortunately, classical logic cannot deal with plausible. Only with absolute. Probability theory solves this problem by measuring plausibility on a 0-1 scale, instead of being stuck at the extremes. Zero is impossible. One is certain. All the values in between represent degrees of uncertainty.
Let’s put this in mathematical terms!
The theory of probability
In a mathematical sense, probability is a function that assigns a numerical value between zero and one to various sets that represent events. (You can think about events as propositions.) Events are subsets of the event space, often denoted with the capital Greek letter omega (Ω).

There are two properties that make such a function a proper measure of probability:
the probability of the event space is one,
and the probability of the union of disjoint events is the sum of probabilities.
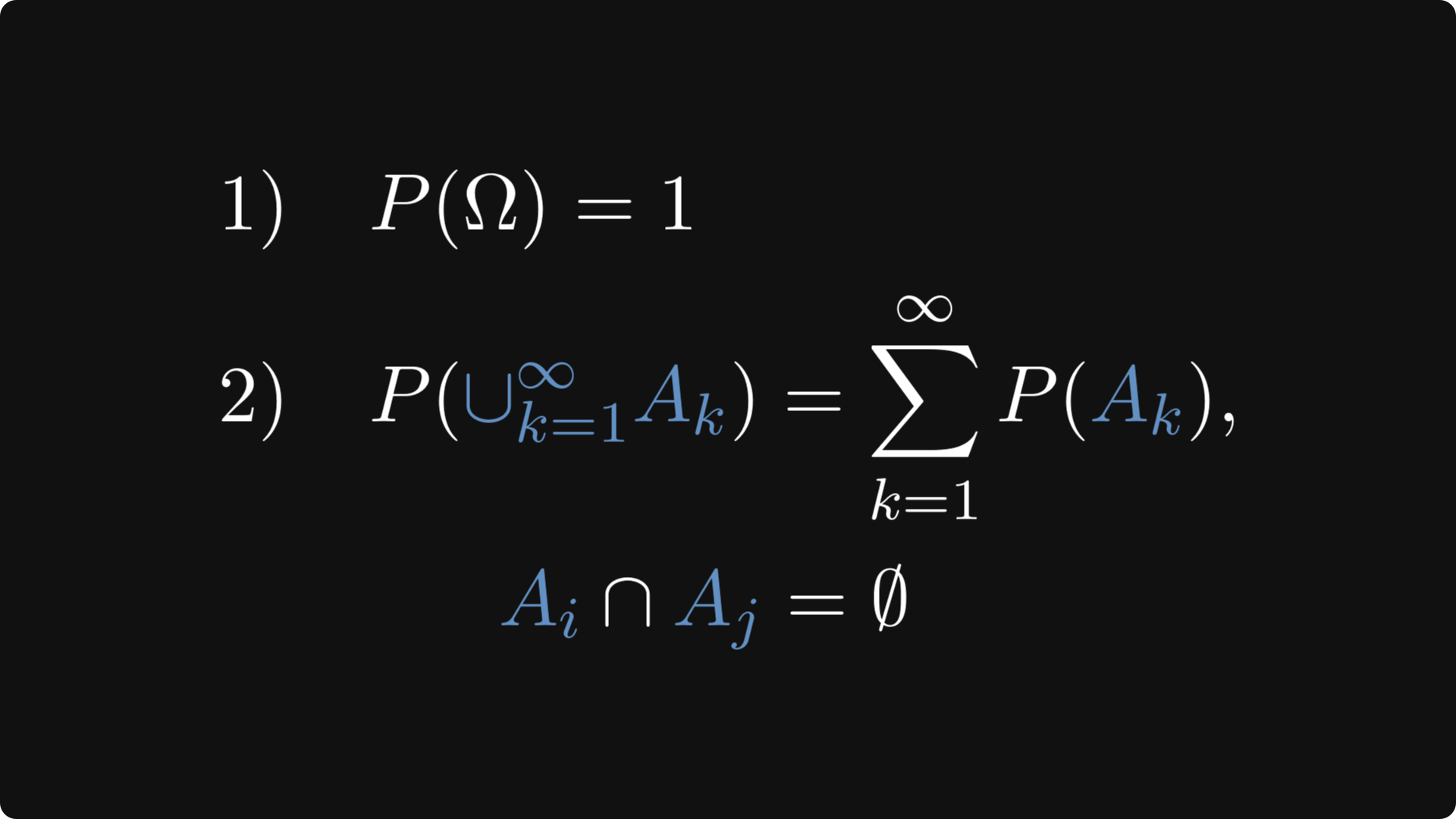
As logical connectives can be represented in the language of set theory, set operations translate the semantics of logics into probabilities. Intersection is joint occurrence of events. Union is the occurrence of either one.

If this is the case, what is the probabilistic analogue of the implication? You know, the connective that is the pillar of thinking.
Connecting cause and effect
How can we establish a probabilistic link between cause and effect? In classical logic, events are interesting in the context of other events. Before, implication and modus ponens provided the context.
Translating to the language of probability, the question is the following. What is the probability of B, given that A is observed? The answer: conditional probabilities.
If A has occurred, we can restrict our event space to A and study probabilities in this microcosms. Mathematically, this is the same as taking the ratio of the joint occurrence and the condition.

Why does conditional probability generalize the concept of implication? It’s easier to draw a picture, so consider the two extreme cases below. (Recall that implication corresponds to the subset relation.)

More intricate relations between A and B can be expressed as well. Again, pictures tell a lot more.


Thus, the “probabilistic modus ponens” goes like this:
P(B | A) ~ 1.
A.
Therefore, B is probable.
This is quite a relief, as now we have a solid theoretical justification for most of our decisions. Thus, the diagnostic process that kicked up our investigation makes a lot more sense now:
P(flu | headache, muscle fatigue, sore throat) ~ 1.
“Headache and muscle fatigue”.
Therefore, “flu” is probable.
However, there is an issue. (Surprise.)
How do we estimate the conditional probability in practice? It’s not as simple! Mathematical statistics and machine learning were founded upon this question.
The inference problem
Our problem is simple: we observe an effect (i.e., symptoms) and want to infer a cause (i.e, flu). To build an insightful mental model, we'll use some sweet abstraction.
Instead of talking about the flu and its symptoms, we'll use balls and urns. Mathematics is powerful because we are able to translate problems into coin tosses, balls, urns, and other simple objects. It’s time to take advantage of this.
Balls and urns
The toy problem is simple: we have two urns in front of us, both are full with red and white balls. Say, urn 1 contains 40 red balls and 10 white ones, while urn 2 has 25 red and 25 white.

Our friend randomly picks an urn, reaches in, and takes a single ball out. The urns are behind a curtain, so we can’t see anything; and selecting each urn is equally likely. She shows the ball, which is red.
The question is simple: what is the probability that the ball came from the first urn?

Intuitively, it should be larger than 50%, as the first urn had more balls.
The exact solution also seems straightforward. Can’t we simply use the definition of conditional probability?

Upon a closer look, we notice that calculating the joint probability is problematic. Fortunately, there is a solution. Unlike classical logic, probability allows us to “reverse the implication”. This would be splendid, as the probability of picking a red ball from the first urn is easy to compute.

So, how is this done? Enter the Bayes formula.
The Bayes formula
I’ll start by introducing a more general terminology. Let’s call event A the “evidence” and event B the “hypothesis”. The situation is clear. Upon gathering evidence (in form of data or other observations), we formulate a hypothesis. We want to infer whether our hypothesis is true. (If this seems abstract, feel free to think of the urn problem. There, our evidence is the event “the selected ball is red”, and our hypotheses are “urn 1” and “urn 2”.)
With some clever algebra, the conditional probability can be massaged until we reverse the role of the condition and the event. (As the calculation below shows.)

There are profound lessons hidden beneath this simple calculation.

The Bayes formula allows us to update our “probabilistic propositions“ given new evidence. Not so surprisingly, this process is called Bayesian inference.
The formula itself is overloaded with information. Let’s walk through it term by term.
First, the result: the posterior. This is what we are interested in, as it describes the plausibility of our hypothesis.
On the right side, we have three terms: the likelihood, the prior, and the evidence.
The likelihood quantifies how plausible would observing the same evidence would be, given our hypothesis is true.
The prior is the probability of the hypothesis without any evidence. This is tricky to estimate in practice, which is often the Achilles tendon of Bayesian inference.
And finally, the marginal, giving the probability of observing the evidence. The marginal is often impossible to compute, as it can be a sum with millions of terms, or a really complex integral.
The good news is, the marginal doesn’t matter at all. Let’s clear up the confusion!
The intractability of evidence
So, about the marginal! In the urn problem, we have two possible hypotheses: “urn 1“ and “urn 2“. In this case, the likelihood of our example is split into two parts.

In practical scenarios, we typically have much more than two hypotheses. Just like it’s illustrated below.

Two hypotheses are manageable, but things can get complicated quickly. For instance, if our hypothesis is a multi-parametric model (instead of the binary variable “urn 1“ or “urn 2“), the marginal takes the form of a high dimensional integral.

Such integrals are impossible to calculate, even for models with a few hundred parameters. (And models often have much, much more.)
We call this phenomenon the intractability of evidence.
The good news: we don’t need the marginal at all! As the marginal does not depend on the hypothesis, we can omit it without affecting the posterior.

Now that we have all our ducks in a row, how can we make an informed decision?
The maximum a posteriori (MAP) estimation
We have collected evidence and formulated multiple hypotheses to uncover the cause behind the observed evidence. How to decide which one is the most likely?
It’s simple: the one with the largest likelihood.

This is the maximum a posteriori estimation, as we accept the hypothesis that maximizes the posterior probability. Since this maximum does not depend on the marginal, we are free to ignore this term. We have just seen that the marginal can be impossibly difficult to compute, thus omitting it is a relief.
Affirming the consequent
Let’s revisit our initial problem: “headache, sore throat, muscle fatigue → flu“. We know that this is not certain, only plausible. Yet, the reverse implication “flu → headache, sore throat, muscle fatigue“ is almost certain.
When naively arguing that the evidence implies the hypothesis, we have the opposite in mind. Instead of applying the modus ponens, we use the faulty argument
A → B.
B.
Therefore A.
This is called affirming the consequent, and it’s completely wrong from a purely logical standpoint. However, the Bayes theorem provides its probabilistic version. The proposition A → B translates to
P(B | A) = 1,
which implies that if B is observed, A is more likely.

This is good news, as reversing the implication is not totally wrong. Instead, we have the following “probabilistic affirming the consequent”.
A → B.
B.
Therefore, A is more probable.
Finishing up
With this, our reasoning process is complete. To recall, the issue with arguments like “if you have muscle fatigue, sore throat, and a headache, then you have the flu“ is that
the symptoms can be caused by other conditions,
and in rare cases, the flu does not carry all of these these symptoms.
Yet, this kind of thinking can surprisingly effective in real-life decision-making. In this post, we have extended our reasoning toolkit with inductive methods in three steps:
generalized the binary 0-1 truth values to allow the representation of uncertainty,
defined the analogue of “if A, then B“-type implications using conditional probability,
and came up with a method to infer the cause from observing the effect.
These three ideas are seriously powerful, and their inception has enabled science to perform unbelievable feats. Like teaching machines how to think.
References
If you would like to read more, I have three books to recommend.
For a quick and practical introduction into Bayesian inference, check out Think Bayes by Allen Downey.
However, if you are looking for a more serious academic treatment on probabilistic thinking, Probability Theory: The Logic of Science by E. T. Jaynes is the way to go. It is hard to read, and ~700 pages long, but this is (probably) the best reference on the subject.
Finally, to highlight the power of probabilistic thinking in real life, Thinking in Bets by Annie Duke. Unlike the previous two, this is not an academic textbook, but this’ll have the biggest potential impact on your life. If you want to use the power of probabilistic thinking to make better decisions in your life, this is the book you want to read.
Aren’t the explanations in the legend of the figure “Probability and set operations” swapped?
Great article. I love how math simplifies things, by making reasonable assumptions.
In the applied sciences world, the multiple lines of evidence approach is preferred.
This is because nature is complicated and false positive or false negative results often “switch signs” with time.