
Vectorization in theory
Making expressions do more, faster

There’s a pattern in machine learning that blows my mind every time, even though I’ve seen it more than I can count.
Look at this expression:
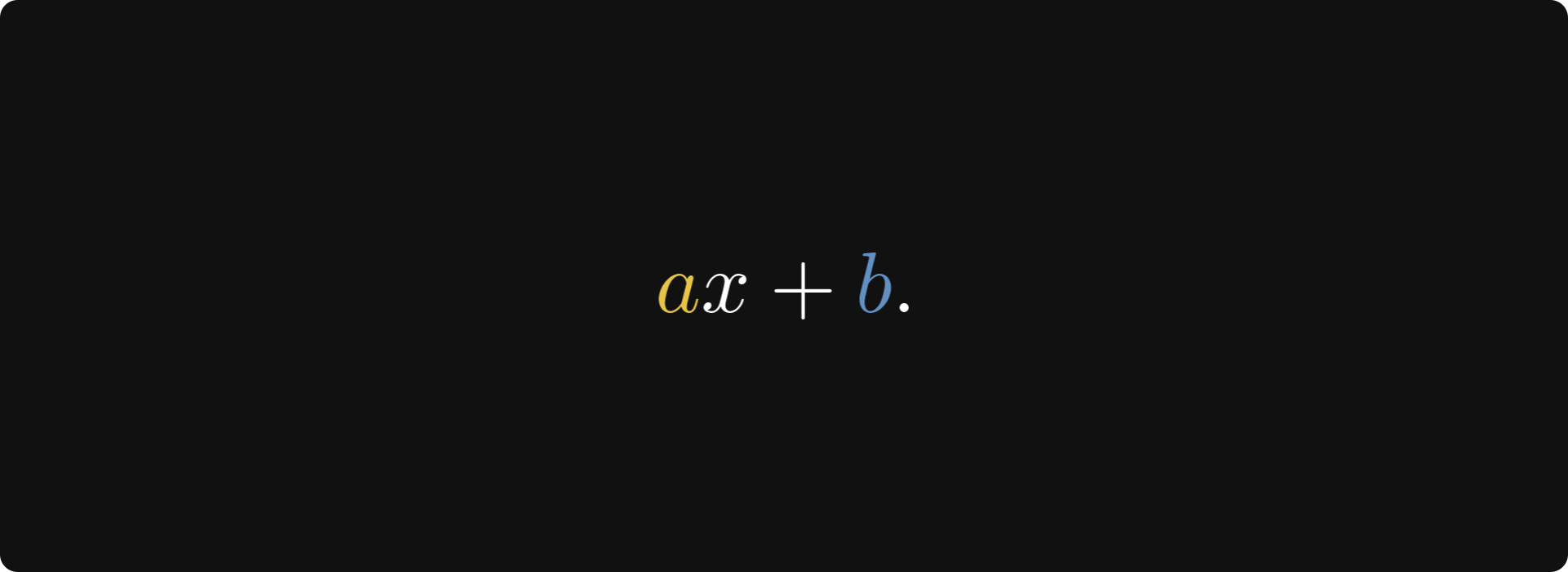
Yes, I know. You are more than familiar with linear regression; we are not here to discuss that. I want to share a wonderful mathematical principle with you, learning through the example of linear regression.
Depending on what we understand by a, x, b, +, and ·, the expression “ax + b” can either be the very first machine learning model a student encounters or the main component of a powerful neural network.
Its evolution from basic to state-of-the-art was shaped by the two great forces of mathematics:
generalizing the meaning of simple symbols such as + and · to make them do more,
and then abstracting the complex symbols into a-s, b-s, and x-es to keep them simple.
This dance of generalization and abstraction is the essence of mathematics; it’s why we can treat functions as vectors, use matrices as exponents, build the foundations of mathematics by dr…
